IndexedHeap
Priority queue that supports item update

Introduction
A heap organizes items into a tree structure and maintians the invariant such that the value of parent is always smaller than both the left child and right child (WLOG, talking about a min-heap).
Python has the built-in library heapq implementation.
The default heap has some constraints/ inconveniences:
- You can only retrieve/ pop element at the top.
- If you need to update an item, you may want to call internal functions like
_siftup()or_siftdown()depending on whether the value is increased or decreased. - You can not directly remove an item in the middle of the heap.
- You can not locate an item's position in a heap directly.
Towards this end, I build the IndexedHeap template. It can be used in following scenarios:
- Maintain a priority queue, whose item value can be updated. This is handy in an SPFA algorithm. You can make sure there is no duplicate nodes in the queue and at the same time be able to update their value. (example behind)
- One element has multiple attributes. Solving the problem requires efficiently calculating minimum of multiple attributes. With the help of indexed heap, you can maintain multiple heaps of ordered attributes and connect them via a common index. You can lookup extreme value from one heap and arbitrarily remove element from another heap via index.
Implementation of IndexedHeap
# min heap
class IndexedHeap:
'''
Every element is (index, item) format.
The index is any arbitrary idenfifier you can use to look up/ pop a heap item
'''
def __init__(self):
self.heap = []
self.hash = {}
def extreme_item(self):
'''
The bottom element of the heap.
min by default.
'''
return self.heap[0][0]
def extreme_index(self):
return self.heap[0][1]
def pop_item(self):
item = self.extreme_item()
self.remove_by_heap_pos(0)
return item
def pop_index(self):
index = self.extreme_index()
self.remove_by_heap_pos(0)
return index
def has_index(self, index):
return (index in self.hash)
def size(self):
return len(self.heap)
def add(self, index, item):
self.heap.append((item, index))
self.hash[index] = len(self.heap) - 1
pos = self._siftdown(0, len(self.heap) - 1)
return pos
def remove(self, index):
pos = self.hash[index]
return self.remove_by_heap_pos(pos)
def remove_by_heap_pos(self, pos):
removed_item = self.heap[pos]
del self.hash[removed_item[1]]
self.heap[pos] = self.heap[-1]
self.heap.pop() #list pop, remove last element
if pos < len(self.heap):
self._siftup(pos)
self._siftdown(0, pos)
def update(self, index, item):
if self.has_index(index):
self.remove(index)
self.add(index, item)
# https://github.com/python/cpython/blob/108e45524d5b2d8aa0d7feb1e593ea061fb36ba4/Lib/heapq.py#L205
def _siftdown(self, startpos, pos):
heap, hash = self.heap, self.hash
newitem = heap[pos]
# Follow the path to the root, moving parents down until finding a place
# newitem fits.
while pos > startpos:
parentpos = (pos - 1) >> 1
parent = heap[parentpos]
if newitem < parent:
heap[pos] = parent
hash[parent[1]] = pos
pos = parentpos
continue
break
heap[pos] = newitem
hash[newitem[1]] = pos
return pos
# https://github.com/python/cpython/blob/108e45524d5b2d8aa0d7feb1e593ea061fb36ba4/Lib/heapq.py#L205
def _siftup(self, pos):
heap, hash = self.heap, self.hash
endpos = len(heap)
startpos = pos
newitem = heap[pos]
# Bubble up the smaller child until hitting a leaf.
childpos = 2*pos + 1 # leftmost child position
while childpos < endpos:
# Set childpos to index of smaller child.
rightpos = childpos + 1
if rightpos < endpos and not heap[childpos] < heap[rightpos]:
childpos = rightpos
# Move the smaller child up.
heap[pos] = heap[childpos]
hash[heap[childpos][1]] = pos
pos = childpos
childpos = 2*pos + 1
# The leaf at pos is empty now. Put newitem there, and bubble it up
# to its final resting place (by sifting its parents down).
heap[pos] = newitem
hash[newitem[1]] = pos
return self._siftdown(startpos, pos)
Example: SPFA
Example: LeetCode 2577. Minimum Time to Visit a Cell In a Grid
It is a typical shortest path problem. The key observation is that, once you reach a cell, you can always revisit the cell at even steps later. We can quickly validate if the problem has a solution by looking at cells (0,0), (0,1), (1,0) . If there is no blocking issue to start with, you can reach any cell and it is a matter of time.
Suppose we already know an interim solution (current optimal value) to reach cell (i,j), it is easy to expand to four directions (one cell being (ii, jj)) and determine if going from source to (ii, jj) via (i, j) is more efficient ("relaxing"). If so ("relaxed"), we shall update the current known optimal for (ii, jj) and then put it back to the queue so it can further relax other nodes.
The "queue" mentioned above can be two data structures:
- A normal priority queue. In this way, we can always expand from the
(i,j)that has minimum known value, giving a better chance of finding optimal for other nodes. This is a good heuristic. Drawback is that a relaxed node(ii, jj)might be already in the priority queue, but we don't have an efficient method to look it up, so the enqueue step results in duplicate values. In this way, the priority queue gets longer and longer and costs more time (logarithmically increase thanks to the heap structure). - A set. In this way, we can ensure no duplicate items in the active set of nodes. However, set pop is not ordered, so there is a good chance that some nodes are relaxed multiple times, because the later popped items have better route on shortest path.
Using an indexed heap, we can nicely solve the above issues. The overall codes are as follows:
class Solution:
def minimumTime(self, grid: List[List[int]]) -> int:
m, n = len(grid), len(grid[0])
if grid[0][0] > 0:
return -1
if grid[0][1] > 1 and grid[1][0] > 1:
return -1
opt = []
for _ in range(m):
opt.append([float('inf')] * n)
opt[0][0] = 0
ih = IndexedHeap()
ih.update((0, 0), 0)
dirs = [(1, 0), (0, 1), (-1, 0), (0, -1)]
while len(ih.hash) > 0:
i, j = ih.pop_index()
for di, dj in dirs:
ii = i + di
jj = j + dj
if 0 <= ii < m and 0 <= jj < n:
new = opt[i][j] + 1
if new >= grid[ii][jj]:
pass
else:
delta = grid[ii][jj] - new
if delta % 2 == 1:
delta += 1
new += delta
if new < opt[ii][jj]:
opt[ii][jj] = new
ih.update((ii, jj), new)
return opt[m - 1][n - 1]
Example: Connect Two Heaps
Example: LeetCode: 218. The Skyline Problem
Given a list of (left, right, height) tuples representing the buildlings, find the skyline.
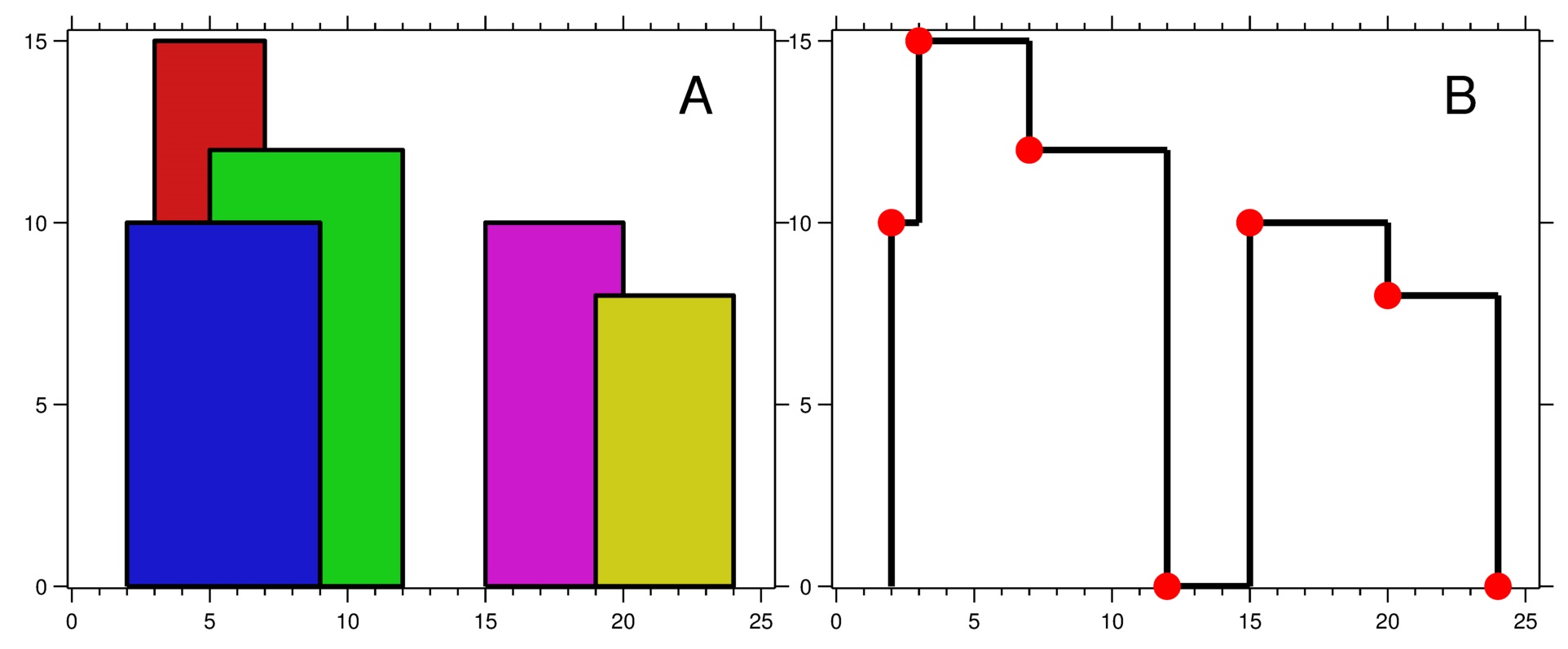
We can sort the list by left and apply a scan line algorithm across all left positions to find critical points. The key complexity of this problem lies when there are overlapping buildings. Suppose we maintain a set of current overlapping buildings, there are two sub problems we need to solve:
- Given the current scanning horizontal location
x, determine if we need to pop out some buildings from the overlapping set. At a givenx, we can pop out all the buildings whose right side is smaller thanx. In order to find "all buildings whose right < x", we can:- Find the building with minimum right and test if it is < x:
- If so, pop the building and continue the process.
- If not, all the right in our set are >= x, so we don't further pop anything
- Find the building with minimum right and test if it is < x:
- Query the max height from the overlapping set, combining the with scanning horizontal location
x, the point(x, max_height)is a critical point.
The first can be achieved with the min-heap of right. The second can be achived with the max-heap of height. Note that in the first step, we need to pop out items sometimes. It is easy to pop out min item from the heap (as a built in feature of normal heap). However, it becomes not so straightfoward to pop out the same building from the max-heap of height.
This is where the IndexedHeap can come handy.
# Test the indexed heap functionality
# case from https://leetcode.com/problems/the-skyline-problem/
# The skyline problem
buildings = [2,9,10],[3,7,15],[5,12,12],[15,20,10],[19,24,8](https://hash.hupili.net/291037155121215201019248/)
ih_height = IndexedHeap() # min heap; use as max heap
ih_right = IndexedHeap() # min heap; use as min heap
critical_points = []
i = 0
buildings.append((float('inf'), float('inf'), 0))
while i < len(buildings):
b = buildings[i]
print(i, b)
print(ih_right.hash, ih_right.heap)
print(ih_height.hash, ih_height.heap)
l, r, h = b
if ih_right.size() == 0 or ih_right.extreme_item() > l:
print('add new')
# l is the next scan line
x = l
ih_right.add(i, r)
ih_height.add(i, (-h, h))
y = ih_height.extreme_item()[1]
i += 1
else:
print('pop existing')
x = ih_right.extreme()
ii = ih_right.extreme_index()
ih_right.remove(ii)
ih_height.remove(ii)
if ih_height.size() == 0:
y = 0
else:
y = ih_height.extreme()[1]
critical_points.append((x, y))
print(critical_points)
Note on the template
Firstly, the update() method is not the most efficient at implementation level. It takes two \(\log N\) operations to remove and add the item. One can optimise it by directly applying the siftup or siftdown algorithm. This is left to future work.
Second note is about the min/max feature. We only implemented the min-heap here, similar to that of the standard library. If you need a max-heap, the common practice is to put a tuple (-value, value, other_data...) . If this way, it is a max-heap based on value. You can retrieve original value and auxiliary data from the remaining of the tuple.
Third note is that the index can be anything that is hashable, i.e. that can be used as key of collections. It does not have to be an integer (like normal sense of "index"). It can be a tuple.
