Quick Restyling with Stable Diffusion and Control Net on Mac
title says all

I'm using Mac M1 2021 version. The steps to bring up the UI:
- Clone ConfyUI .
- Setup accelerated pytorch on Mac.
- Download SD-XL, and put the files under
models/checkpoints. I chosesd_xl_turbo_1.0.safetensors. - Download vae and put the files under
models/vae. I chosediffusion_pytorch_model.safetensors. - Download control net, I chose
-lora-sketch. Put the files inmodels/controlnet. - Launch local server
python main.pyand find the UI at: http://127.0.0.1:8188/
A sample workflow and sample input/ output are as below:
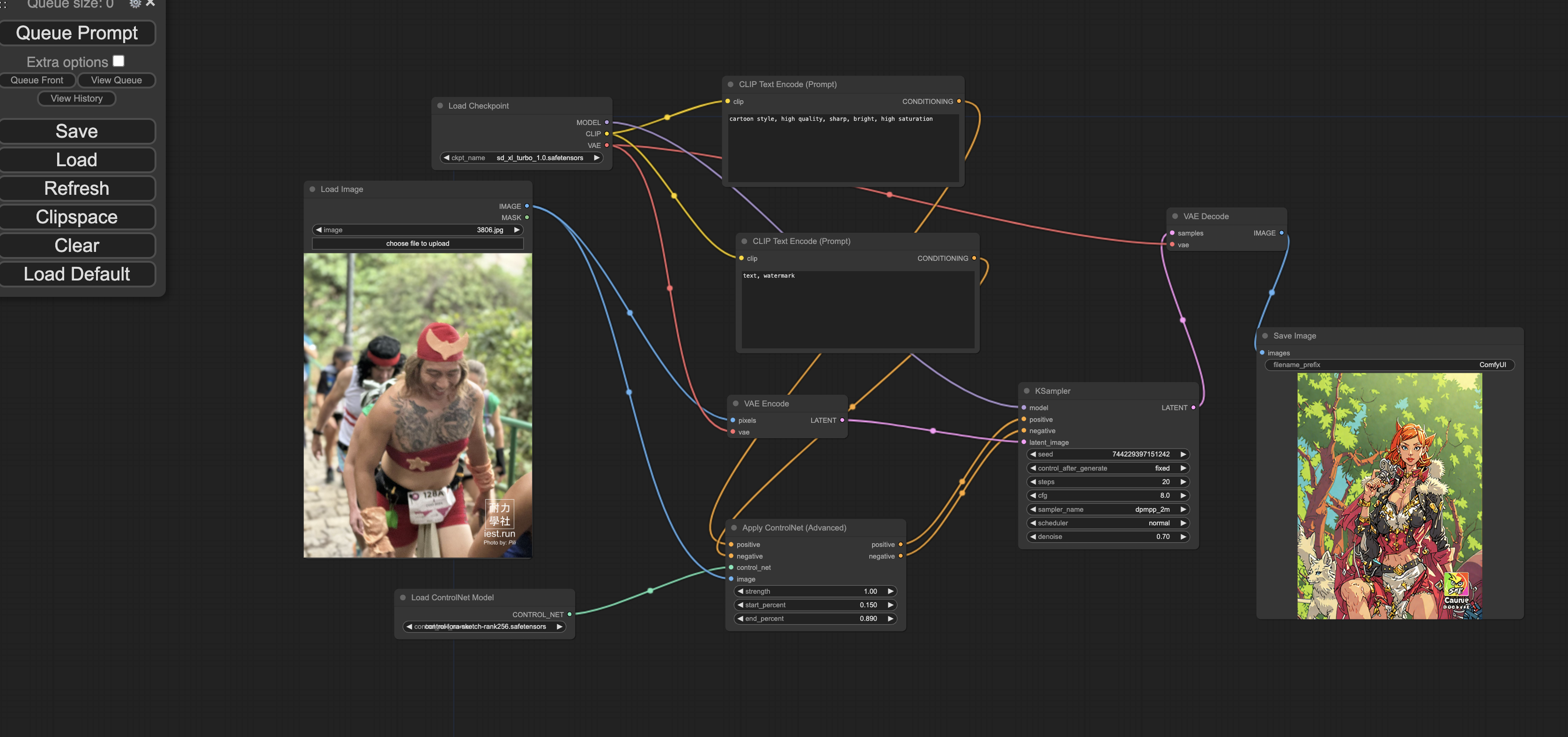
Key models:
- Stable Diffusion: Key idea is to progressively add noise to an image so that it becomes complete random at certan step. The process is called foward diffusion. If we can learn a structure to identify the noise component, then the reverse diffusion turns a random seed gradually into a legible image. The diffusion process is conducted in the latent space to save computation resources. The link between latent space and pixel space is VAE. In order to make the result of reverse diffusion meaningful, we need to guide the model to learn tailor made noise structure. The guide is given by CLIP.
- CLIP: The pre-trained model on a variety of (image, text) pairs. This is the model that turns positive and negative text prompt into the image latent space and used by Sampler to guide the direction of denoising.
- VAE. Variational AutoEncoder. AE is a pair of neural networks, where encoder reduces input dimensions and decoder maps lower dimension (latent) to higher dimension (pixel). The "Variational" part plays a role at encoder stage. Compared to normal deterministic encoder, the variational encoder maps input high dimension vector to a distribution in latent space. Here is a good read from history developments to cutting edge status quo.
- KSampler. The core component and most time consuming part. The Sampler takes current image and estimate the noise component based on CLIP output to guide the denoising direction. There are many sampling method/ parameters to choose from. Here's a comprehensive guide to samplers.
- ControlNet. A family of models that make part of the network locked and part of the network trainable. It can be used to retain some key features of input image, e.g. sketches, faces, gestures, etc. Find some examples of controllable features here.
- GAN. A pair of neural networks that works against each other. One tries to make output image as real as possible and another tries to distinguish real image and generated image. After some iterations, both are very good at doing their respective jobs, and the generative part can be useful for a variety of tasks, e.g. upscaling. One commonly used example is RealESRGAN.
Common parameters:
- Positive/ Negative prompt -- Text to condition the diffusion process. If ControlNet is not used, the influence of text prompt is almost paramount.
- Denoise -- The target denoise, aka the ratio that are allowed to be different from the input latent image. Higher the value, the more variety, but less close to original input text/ image.
- Steps -- Steps control the "noise schedule" during sampling/ denoising phase. The more steps, the more added details, due to less truncation erorr, but instead incurs more computation time.
Where to download models:
- https://huggingface.co/ -- Most main stream models collection.
- https://civitai.com/ -- A variety of tailored image models, for restyling/ upscaling/ learning image parts/ etc.
Uplevel:
- ComfyUI-Manager is like a package manager (
pip,npm) for a language. It can help to automatically download missing nodes and models, which is handy when you try to quickly bootstrap from other's workflow. - InstantID is zero shot identity preserving generator. You may refer to this link to manually download some essential parts.
Caution:
- Disk space -- The models can easily be 100M+ to 10GB+.
- The model execution could be slow on notebook.